From the Archive: $CNX
2848 words | 14 minutes
Note: The following blogpost is part of a series of old writeups I did on various DePIN and DeFi projects across the latter half of 2024.
It’s likely that some of the content is out-of-date or no longer reflective of the current state of the project discussed. I’ll leave notes here and there for some updates, but I’m keeping those minimal. Regardless, I’ve decided to post these here anyways for posterity. The writing style may be a little inconsistent and unstructured, but hopefully the reads are still entertaining.
A Look into “Crynux”
The Problem Statement
Crynux posits itself as an answer to the problem of decentralized artificial intelligence.
As brought up by its creators and the author (Aaron Yuasa) of its Whitepapers (link, link), large deep learning models and big AI present a set of challenges:
- Centralization and monopolization
- Privacy and security risks from centralized operations
- Lack of transparency and accountability
- Lack of incentive mechanisms to curate datasets, generate feedback for RLHF, etc.
These are all fair arguments to be made, especially with the sheer dominance that OpenAI, Microsoft, Google, Meta etc. has when it comes to AI. Yes, there are open source means of running powerful LLMs yourself, but there’s the intrinsic barriers in hardware cost, technical knowhow, etc.
Decentralization of AI follows in the same footsteps as the many laissez-faire “democratizing XYZ” products targeting different sectors that has come before it. However, decentralization of AI in particular is evidently non-trivial. Some issues that have been accurately pinpointed include:
- The need for verifiable decentralized computations, especially for large models that involve a lot of complex calculations
- Decentralized computing power should have low latency and be able to overcome bandwidth limitations
- Multi-Party Computation, Fully Homomorphic Encryption and Zero Knowledge Proofs are all wildly impractical to be applied to deep learning due to complexity and computing cost
Crynux purports itself as a practical means of accomplishing decentralized AI, leveraging a consensus algorithm and a “not proof of stake” tokenomic model.
Network Architecture
Crynux is several things, but to clarify what it is not:
- A means of splitting the compute needed for powerful models
- A means of generating cryptographically provable deep learning inferences
- A serverless network
To simplify in one fell swoop: The Crynux network is yet another P2P AI hookup system.
For the majority of the discussion, we will be looking at Crynux’s image generation task (the “Hydrogen Network”, accessible both on https://ig.crynux.ai/ and their Discord bot, “HappyAIGen”) as the text generation/GPT task seems to be… very non-functional at the time and not particularly fleshed out yet. [Update 15/01/2026: The project has since moved on to the Helium network! So these points are all definitely out of date.]
The native token of the network is CNX, which is the currency used to pay for inference tasks and the reward token that node operators/compute providers will receive.
For the timebeing, the project is being run on the Dymension Blumbus Testnet (explorer) [Update 15/01/2026: This testnet explorer no longer functions. I don’t know if any archives of it exist. Now, I understand that testnets are but testnets and there’s no expectation that all the TXs are archived and whatnot once the testnet is abandoned, but it still feels a bit antithetical to the whole… ye’know. Immutable. Indestructible. Censorship free. Et cetera.]
The Relay
Stated to be “a compromization (sic) on the decentralization of the network”, the relay is where task arguments and the subsequent inferences are sent to, acting as a middleman between the end user and the compute provider. It’s been deployed on https://relay.h.crynux.ai/
The creators recognize that there are issues with an off-chain solution like this, in particular if their server goes down, leaving tasks in limbo and there being no data for the on-chain verification to work off whether its a server failure or the nodes cheating.
Nodes
These are our compute providers of the network. Every node stores local copies of the models that the end user would like to run (e.g. Stable Diffusion) and simply runs inferences and submits them to the relay. We will look at the consensus protocol, their answer to compute verification, later.
Applications and the Blockchain
Applications that leverage the Crynux network can use APIs that serve as bridges to on-chain operations. The idea is for an end-user to simply connect a wallet with some CNX balance, make their requests and have a largely seamless experience.
State of the Network
We can actually see how the network is doing here: https://netstats.crynux.ai/
We see quite a number of RTX A4400 and RTX A4500, which retail for about 1500 USD. [Update 15/01/2026: 1700 USD.] Whether there are actually that many GPUs on the network or if they’re being spoofed…
Tokenomics
There’s a handy disclaimer that says that this is all work in progress [Update 15/01/2026: And the page is gone now…], so let’s be brief with this.
On mainnet deployment:
- Total supply will be 8,617,333,262 tokens
- 20% of tokens will be minted on release to bootstrap the network
- The remaining 80% will be minted and distributed via node and task mining
Node Mining
- 40% of tokens will be given to nodes for being online
- Tokens rewarded will be based on the node’s “Quality of Service” (QoS) while online
- We will look at the QoS later
- Token rewards will exponentially decay
- This is meant to incentivize bootstrapping
Task Mining
- 40% of tokens will be given to nodes as rewards for completing tasks
- Distribution is based on the month’s total count of tasks
- We naively assume that usage will grow exponentially, then use the Avrami equation to determine the token rewards
- The Avrami equation has three stages
- Slow increase, so that the rewards aren’t too high for too few nodes
- Increasing speed in the middle to promote network growth
- A cooldown since there are now enough nodes
- The choice of using Avrami seems to be nerd motivated (it concerns phase changes in chemistry) and isn’t something used in other projects
The Consensus Protocol
This is Crynux’s answer to verifiable compute: a not exactly Proof of Stake but loosely PoS system that relies on consensus to agree on a task’s output.
- When you send a task to the blockchain, three nodes will be chosen at random to execute the same task on similar hardware with the same arguments.
Sidenote: Although the docs talk about Verifiable Random Functions and Zero Knowledge Proofs (ref), discussing this as a means to reduce the overhead of validation, none of this is present in the project as is, nor does it make much sense given that 1) it means not every task is validated properly and 2) the compute cost for ZKP. [Update 15/01/2026: And I mince my words. The project has since been updated to implement VRFs and ZKPs. The updated verification system can be found here.]
-
Since it is basically impossible to generate identical images without identical hardware (which is recognised by the creators), Crynux uses a “Perceptual Hash” (pHash), followed by a Hamming Distance calculation between pHashes to check for similarity (we will look at the technical implementation later).
-
To prevent gaming by intercepting other nodes results, the pHash and a random number are hashed together as an on-chain commitment first to indicate task completion, and after all submissions, then pHashes will be disclosed for comparison
Staking and Slashing
This is supposedly not PoS.
All nodes participating will stake some amount of CNX in order to be deemed eligible to serve as a compute provider. If someone were to act as a malicious node and submit fake results to the network, if this is recognised during the process (e.g. pHash exceeding the Hamming distance threshold), then their CNX will be slashed as a penalty.
Obviously, systems are not failure proof and slashing should be fairly executed. If 2 or more nodes report an error executing the task, the task is aborted and your CNX will not be slashed. If a node goes offline (lets say it crashed), the task can also timeout, in which your CNX will not be retroactively slashed.
This presents obvious ways to game the system that the creators recognise:
- An attacker waits to become 2 of 3 nodes selected for the same task. If this happens, they can submit a false result via both nodes, screwing over the third node and gaining a reward for a fraudulent result.
- If the above does not occur, an attacker should simply timeout so that it isn’t penalized.
There are some interesting equations proposed in the docs that seek to reduce the possible profitability of such attacks, with the common conclusion that to mitigate these, the staking amount should be increased over time. Whether this will actually be implemented is to be seen.
For reference, as of right now, you stake a fixed amount of 400 CNX on the testnet.
Effectiveness
Right now, the Consensus Protocol proposed here is fairly logical, and in an ideal world where there are enough nodes operating and the pHashes work as intended, it would end up being a relatively effective solution to the problem of verifiable compute.
As previously stated, actual verifiable compute is virtually impossible to accomplish as of right now due to the sheer complexity involved in generating Zero Knowledge Proofs for deep learning or the compute cost of Fully Homomorphic Encryption, so a PoS-esque system that hinges on consensus is about as good as you can get at this point.
But now this begs the question: can I game this, and is this scalable?
Here, we see a few holes to poke and prod at:
- How easy is it to spoof a node (that responds with completely fake results)?
- An attacker can trivially increase the odds of hitting that 2/3 for a computation through sheer volume, with the only cost being the amount needed to stake per node.
- If the approach to defeat such an adversary would be to increase the staking amount, how badly are you screwing over legitimate compute providers?
- How easy is it to spoof an inference result?
- Our consensus algorithm hinges on the effectiveness of the pHashes in verifying output. Is the pHash gameable? Can I get away with a lower compute method?
- Docs recognise this as a potential issue, to which the response is “as long as the result is similar enough to be accepted by the application, it is fine to the network”
- Right now, we are working with simpler, older models and small dimensions (512x512). Would such a system continue to work with more advanced models which have even less deterministic results and more complex prompts and larger outputs?
- How easy is it to increase the odds of being chosen as a node?
- Can you make certain task requests that your nodes are more likely to fulfill?
Running a Node
Let’s try running our own Crynux node.
Right now, it seems the network has been deployed on the Blumbus Testnet for Dymension. All the deployed smart contracts source code can be found here and the contract addresses have been baked into the config file for the node.
We’re building it from source rather than using a precompiled binary as we want to tinker with it later…
Observations
- You download around 67 GB of models off the bat
- The models include:
- Stable Diffusion v1.5
- Some Stable Diffusion distribution that seems optimized for generating images of Asian women. No comment.
- Stable Diffusion XL
- GPT2
- Falcon-7B-Instruct
- Controlnet Stable Diffusion (for pose based generation)
- The models include:
- You’ll notice SD tasks coming in every few minutes. This is because this one task:
task_args: {"base_model": "emilianJR/chilloutmix_NiPrunedFp32Fix", "prompt": "best quality, ultra high res, photorealistic++++, 1girl, off-shoulder sweater, smiling, faded ash gray messy bun hair+, border light, depth of field, looking at viewer, closeup", "negative_prompt": "paintings, sketches, worst quality+++++, low quality+++++, normal quality+++++, lowres, normal quality, monochrome++, grayscale++, skin spots, acnes, skin blemishes, age spot, glans", "task_config": {"num_images": 1, "safety_checker": false, "seed": 982883}}
keeps getting requested. In fact, the vast majority of the CNX I’ve earned by running the node has been from this one dummy task that keeps coming in.
- Looks like after I started a spoofed node I started receiving LLM tasks with the prompt
What is LLM(large language model)? How can I use it?. Cool. - Timeout errors do occur (not from my end, that is), although not too frequently.
Spoofing
Spoofing is trivial as the Crynux node is primarily composed of the crynux_server and crynux_worker modules that you build yourself. Given that these are python modules, you just need to edit the module files and you’re on your way.
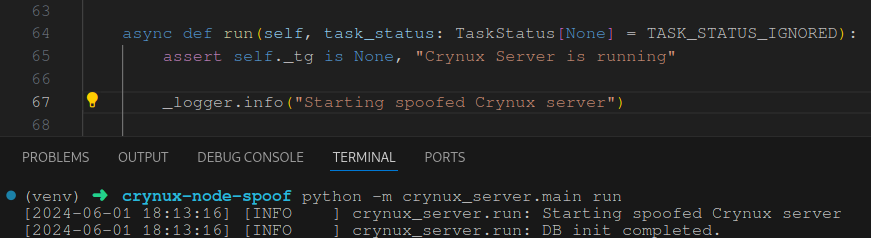
I can spoof my GPU details quite trivially, actually, and this even shows up on the stats page:

Perceptual Hashes
The perceptual hashing algorithm used is goimagehash, and the Hamming Distance calculation is performed on-chain via the Hamming.sol contract, which is called in Task.sol with a threshold value of 5.
In case of unfamiliarity with Hamming distance, it’s a fairly simple algorithm: between two outputs A and B, we step through them bit by bit. If a bit at the same position in output A is different from the bit at that position in output B, we increment the Hamming distance by one. e.g. 10111 and 01100 have a Hamming distance of 4.
The implementation of the pHash itself follows this blogpost.
Is this Gameable?
In terms of using less compute, it could be that you could get away with generating a lower quality image that generates the same pHash. However, it’s quite unlikely that you can generate an image without running a model itself to generate something (although you could probably use a public model API or something) and receive a pHash that is valid.
Task Dispatching
[Update 15/01/2026: The Sybil attack described here probably doesn’t work anymore, but it was a fun experiment at the time.]
Quality of Service
Node quality is evaluated based on:
- VRAM Size
- Setting a shorter timeout
- Having a faster submission speed
And there’s some math that goes along with it
Apparently, the QoS gets actively updated on the fly. This QoS also determines your likelihood of being chosen for a task and your share of token rewards.
So, how much of this is actually implemented?
Looking at QOS.sol we see that your score is determined by this one array TASK_SCORE_REWARDS which awards you more points for being first and less for being last. VRAM and timeout timing play no part.
Also, your score gets zeroed out if your total score is under the kickoutThreshold, which is only 20, so you basically just have to make maybe 4 or 5 good submissions to avoid getting kicked out.
Also, looking at Task.sol, QoS is not actually an influencing factor on your odds of being chosen as a provider. Shucks.
Finding the Right Compute Providers
- When tasks are dispatched, they are graded based on the task type and the VRAM requirement, which filters out GPUs e.g. an intensive image gen task is unlikely to be completed on a laptop RTX 3050 with 4 GB of VRAM.
- Apparently you are also graded by card model? e.g. RTX 4090s are grouped together and RTX 3080s are grouped together. But in the next paragraph it states that it will randomly pick the card model group, so the group with more nodes will have a higher probability of being selected.
- Higher valued tasks are pushed further up the queue. The value of a task is essentially how much a user is willing to pay for the task divided by the task execution time, which is determined… how?
- The task execution time must be known before the task is executed, so that means it has to be estimated, right?
“Is any of this actually implemented?”
- It seems like the
sameGPUflag is only set for the GPT task, which as of right now is basically unusable. - It does seem like when a task is created, a
vramLimitis set, which filters out GPUs. This limit is user determined. - The card grouping does not seem to be implemented at all.
- Task execution time estimation is nowhere to be found. The only determining factor is the task price, which is also user determined.
Is this Gameable?
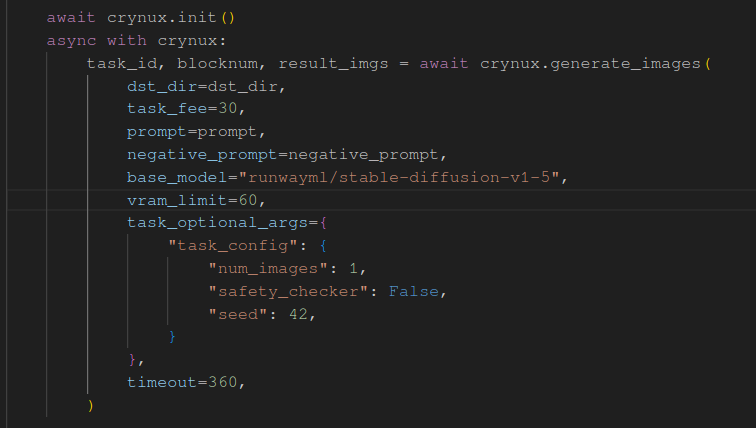
So what if I issue tasks with a minimum VRAM requirement of, like, 64GB, then run a bunch of fake nodes that claim to have that VRAM? If we receive any other tasks, just timeout without much consequence.
No other nodes have that much VRAM, so the task is for sure going to end up with me.
Using the SDK, we can issue a request with a VRAM limit like that:
And we simply skip past the actual inference in the node’s code and just copy a dummy file:
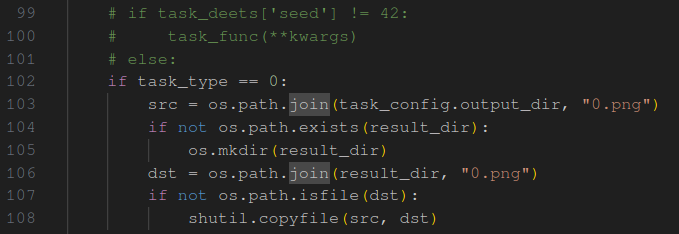
This works!
Here is a tx where I got a payout for a fake task. [Update 15/01/2026: Guess my proof is gone. Boohoo.] Great success.
I did screw it up later on, however, and got my stake slashed. For one, at least that logic functions. But on the other hand, we’ve now proven that a Sybil attack can be performed with the only real cost being the staked tokens!